dmitry_
-
Публикации
56 -
Зарегистрирован
-
Посещение
О dmitry_
-
Звание
Абитуриент
")
-
shaper-сервер
тему ответил в xplorer пользователя dmitry_ в Программное обеспечение, биллинг и *unix системы
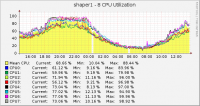
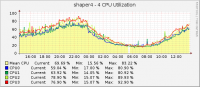
выложу свои наблюдения по этому поводу имеем 2 разновидности серверов, все на платформах супермикро. на первой платформе стоит проц Intel® Xeon® CPU E31220 @ 3.10GHz - 4 ядра, сетевухи: 2 встроенные e1000e и Intel 82576 2х портовая, из них делаются 2 bond, один на вход, другой на выход. Трафик на каждом bond: ~ 150kpps in/out, 1.33Gb/s in и 600Mb/s out в это время видим загрузку CPUs следующую на второй платформе стоит проц Intel® Xeon® CPU E5620 @ 2.40GHz - 8 ядер, с сетевухами картина идентичная первой Трафик на каждом bond: ~ 145kpps in, 111kpps out, 1.25Gb/s in и 480Mb/s out в это время видим загрузку CPUs следующую На обоих машинах крутятся, nat, htb shaping на in/policing на out, и самописный демон для снятия conntrack - видно что 1 камень загружен чуть больше. Можно сделать вывод что 4-х ядерный проц с большей тактовой частотой справляется лучше с задачами, чем более ядерный, но меньшей тактовой частотой. У меня были мысли разогнать Xeon® CPU E5620 @ 2.40GHz, кто-нибудь таким занимался и стоит ли вообще гнать CPU в таких решениях, не выйдет ли это боком? 2-я платформа покупалась с надеждой, что вытянет честные 2Gb/s, но не тут то было, теперь думаю или разогнать CPU или купить 2-проц, платформа позволяет устанавливать 2