


Azamat
-
Публикации
316 -
Зарегистрирован
-
Посещение
Сообщения, опубликованные пользователем Azamat
-
-
Опубликовано · Изменено пользователем Azamat · Жалоба на ответ
Вот такие модули не капризничают
Ethernet1/15
transceiver is present
type is QSFP-40G-LR4
name is OEM
part number is QSFP-40G-LR4
revision is 1B
serial number is CSQLRI30006
nominal bitrate is 10300 MBit/sec
Link length supported for SMF fiber is 10 km
cisco id is --
cisco extended id number is 192
Кто производитель - хз. Но порты выдерживают по 6-8 перетыкиваний без зависания. Нам этого хватает.
Зато есть один зависший порт, воткнули/вынули модуль от FS, ждем нового года для плановой перезагрузки
Eth1/13 eth 40G BAD PORT Reboot at NewYer
На медных кабелях ни разу не замечали подвисаний, как то раз 10-15 втыкали/вынимали.
-
С медными проблем совсем не замечали. Проблема именно с оптическими QSFP+
и если оптический модуль завесил порт, то выкл/вкл порта уже не поможет, только ждать ребута.
-
там может быть debounce timer понастраивать надо ? вроде как он отвечает за реакцию на упавшее.
По qsfp падений не было больше чем полугодия, а те что были - исключительно ночью. Поэтому реально ни на что не сказывалось. Видимо, если от них не требовать невозможного - то вполне себе зверушка.
-
да, у нас в основном 2-4 х 10гиг в портченнел. Нужно не для расширения полосы, а для надежности стыка.
-
Не соглашусь. В сети 66 штук 3064, с pim все в порядке, qsfp на Х версии работают как часы. Портченнелы примерно на 30 шт. есть
Все на одной и той же версии 6.ххх
Заболел первый коммутатор, примерно за 3 года. Стало жалко зверушку, но до причин не докопались. 7 бед - один ресет.
-
нет, все внутри, ничего наружу не выходило ни через один физ. интерфейс.
На всех svi только исходящий (у нас синий по графику), зеленого в плюсе не было нигде. Как будто под себя ср..ть начал, заболел чем то зараза. Вот и хотели понять, как диагноз поставить.
-
После ребута полет нормальный. Продолжаем наблюдение.
-
Опубликовано · Изменено пользователем Azamat · Жалоба на ответ
тв "сыплет" :( это из заметного. Через стандартный IP во влане управления недоступен. Медленно работает консоль, т.к. проц загружен вместо обычных 30-40 проц на 85
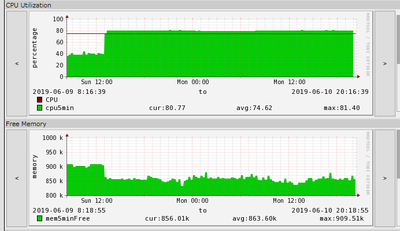
-
Опубликовано · Изменено пользователем Azamat · Жалоба на ответ
Доброго всем дня.
Есть nexus 3064, на нем помимо всего прочего 4 svi интерфейса.
Вчера в одно и тоже время на всех svi возник из ничего нереально большой исходящий трафик - например, обычный трафик на 2 svi - порядка 1,2 гиг на каждом. Сейчас исходящий судя по графику - 560Гиг на каждом.
На 3-м svi обычный трафик 100Кбит/с - влан управления - сейчас на нем исходящий 300Гиг. Доступ только через mgmt порт, через IP адрес на svi управления - скидывается.
Реально, нет событий, к которым можно было бы привязать взрыв трафика. Пытались зеркалировать - ничего не видать, вроде т.к. в зеркало на source vlan идет только rx, а взрывной трафик по tx. А сделать source int vlanXXX не дает. Версия 6.ХХХ
Из странного еще хороший прирост процесса bcm_usd. На физических интерфейсах - ничего примечательного, все как до взрыва трафика. Пытались делать shutdown на int влана управления - мин 10 держали, потом подняли - ничего не изменилось.
В общем может кто подскажет, как можно хоть что-то отдебажить до перезагрузки, которую запланировали на 6 утра ? Может есть возможность убить процесс с HUP ? Сам не нашел, как именно - ибо ремесленники мы.
Добавил график.
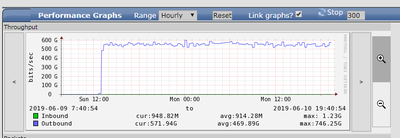
-
У меня есть один аплинк, с которым 2 геогр. разных стыка. С одного из них приходит full, весь виден в netstat -rn | wc -l (за 700К записей), но при попытке его отдать дальше клиенту - уходит где то 2К маршрутов. Причем с другого стыка этого же аплинка и full принимается и анонсируется нормально.
Если в квагге включить побольше логирования - у меня было видно, что от "корявого" стыка приходила какая-то ошибка в опциях при обмене capabilities - на конкретные вхождения в full и после этого re-anounce маршрутов останавливался.
Т.к. победить ту сторону не получилось, то основной full принимается с нормального стыка с аплинком, на второй просто забито, на него default прописан статиком на всякий случай.
Суть - включить побольше дебагов квагги и смотреть, на чем идет затык при обмене данными с аплинком, который тормозит отдачу маршрутов дальше.
Это если предположить, что сами по себе настройки пиров без ошибок. -
Опубликовано · Изменено пользователем Azamat · Жалоба на ответ
в самом первом посте было в общем контексте:
net.inet.ip.fw.one_pass: 0
То ли в 12.0 увели в штатном режиме обработку прерываний в system, то ли х.з. что еще.
Вот роутер на 12.0-stab:
netstat -bdh -w1 -I ix0
416k 0 0 515M 222k 0 46M 0 0
544k 0 0 673M 289k 0 61M 0 0
netstat -bdh -w1 -I ix1
input ix1 output
packets errs idrops bytes packets errs bytes colls drops
229k 0 0 64M 408k 0 492M 0 0
234k 0 0 65M 426k 0 517M 0 0
255k 0 0 68M 447k 0 546M 0 0
257k 0 0 71M 461k 0 562M 0 0
top -PHS
last pid: 63873; load averages: 2.04, 2.20, 2.16 up 30+04:29:51 22:20:40
191 threads: 8 running, 166 sleeping, 17 waiting
CPU 0: 0.4% user, 0.0% nice, 52.3% system, 0.4% interrupt, 46.9% idle
CPU 1: 0.0% user, 0.0% nice, 52.7% system, 0.0% interrupt, 47.3% idle
CPU 2: 0.0% user, 0.0% nice, 54.0% system, 0.0% interrupt, 46.0% idle
CPU 3: 0.0% user, 0.0% nice, 61.5% system, 0.0% interrupt, 38.5% idle
Mem: 26M Active, 1348M Inact, 1050M Wired, 493M Buf, 5596M Free
PID USERNAME PRI NICE SIZE RES STATE C TIME WCPU COMMAND
0 root -76 - 0 384K CPU1 1 206.2H 53.17% kernel{if_io_tqg_1}
0 root -76 - 0 384K - 2 207.1H 49.33% kernel{if_io_tqg_2}
0 root -76 - 0 384K - 3 206.5H 48.67% kernel{if_io_tqg_3}
0 root -76 - 0 384K - 0 202.7H 48.41% kernel{if_io_tqg_0}
здесь тоже вся прерывания в system, хотя:
net.isr.numthreads: 4
net.isr.maxprot: 16
net.isr.defaultqlimit: 20480
net.isr.maxqlimit: 20480
net.isr.bindthreads: 1
net.isr.maxthreads: 4
net.isr.dispatch: direct
+ выпилен Fastforwarding (во всех предыдущих версиях облегчал жизнь),сейчас вместо сделали какой-то tryforward, как зафиксировать его влияние - хз.
до кучи:
interrupt total rate
irq1: atkbd0 2 0
cpu0:timer 2934125667 1125
cpu1:timer 2935059792 1125
cpu2:timer 2933854332 1125
cpu3:timer 2934959046 1125
irq264: ix0:rxq0 61858968128 23714
irq265: ix0:rxq1 75590459238 28978
irq266: ix0:rxq2 75312963992 28871
irq267: ix0:rxq3 75505104647 28945
irq268: ix0:aq 7 0
irq269: ix1:rxq0 90200128638 34578
irq270: ix1:rxq1 97008771872 37188
irq271: ix1:rxq2 96822862993 37117
irq272: ix1:rxq3 96773135031 37098
irq273: ix1:aq 18 0
irq275: ahci0 36970587 14
irq278: em0:irq0 410569352 157
Total 681257933342 261161
Работает как роутер не хуже, но и не лучше других версий, у меня на них базовая 10.3
-
Опубликовано · Изменено пользователем Azamat · Жалоба на ответ
2 минуты назад, Azamat сказал:Плз не разговаривайте с собственными голосами насчет фри в целом. 12.0 нормально работает в режиме роутера.
Если знаете - подскажите. Я выше предлагал удаленный доступ к серверу для умелых (я только ремесленник). Что то не нашлось желающих потратить время на сообщество.
А у меня времени не было чтобы разбираться, почему проц. на 100 проц на 700Мбит/с - а это глубокая ночь, а не на 12% как на 8.4 - ибо стали расти задержки и другие прелести типа запредельного джиттера.
По другому получить рабочую нагрузку мне негде, гонять несколько потоков iperf - не показательно. На людях экспериментировать - не вариант.
Попробовал только direct, hybrid, differed - одно и то же оказалось по факту.
Зато первое правило allow from any to any возвращает проц к 10% загрузки. Т.е. один и тот же набор правил ставит колом 12.0-stab и легко обрабатывается на 8.4
-
Кажется повсюду рекомендации отключать HT.
Что-то изменилось ?
-
Может потому что число ядер в процессоре 6 ? Вот по кол-ву ядер и распределилось по например по net.isr.bindthreads="1"
Performance
-
Итого:
под нагрузкой мост на FB 12.0 оказался полной лажей :
на трафике меньше 1 Гбит/с (который мост на FB 8.4 даже не замечает):
CPU 0: 0.0% user, 0.0% nice, 77.6% system, 0.0% interrupt, 22.4% idle
CPU 1: 0.0% user, 0.0% nice, 77.6% system, 0.0% interrupt, 22.4% idle
CPU 2: 0.0% user, 0.0% nice, 74.8% system, 0.0% interrupt, 25.2% idle
CPU 3: 0.0% user, 0.0% nice, 83.7% system, 0.0% interrupt, 16.3% idle
Mem: 18M Active, 8680K Inact, 276M Wired, 90M Buf, 7479M Free
Swap: 8192M Total, 8192M FreePID USERNAME PRI NICE SIZE RES STATE C TIME WCPU COMMAND
0 root -76 - 0 400K CPU1 1 55:25 81.45% kernel{if_io_tqg_1}
0 root -76 - 0 400K - 3 57:22 80.68% kernel{if_io_tqg_3}
0 root -76 - 0 400K - 2 55:35 74.87% kernel{if_io_tqg_2}
0 root -76 - 0 400K CPU0 0 56:27 69.53% kernel{if_io_tqg_0}
11 root 155 ki31 0 64K RUN 0 21:21 29.24% idle{idle: cpu0}
11 root 155 ki31 0 64K CPU2 2 22:51 24.90% idle{idle: cpu2}
11 root 155 ki31 0 64K RUN 3 21:06 19.16% idle{idle: cpu3}
11 root 155 ki31 0 64K RUN 1 23:01 18.71% idle{idle: cpu1}
0 root -92 - 0 400K - 0 0:57 1.57% kernel{dummynet}
Почему то вся нагрузка на system, хотя net.isr в direct
net.inet.ip.dummynet.io_fast: 1
волшебной крутилки чтобы снизить нагрузку не нашел, возвращаемся на 8.4
-
Вам отдельное спасибо, реплики "Не мешайте ему жить в древнем мире." - очень мотивируют на самостоятельный поиск решений.
-
В общем похоже разобрался.
Причем, как и ожидалось - net.inet.ip.forwarding оказался не при делах, работает при
net.inet.ip.forwarding: 0
Сейчас так режет полосы:
ipfw pipe 100 config bw 64Mbit/s queue 1800
[ 3] 0.0-30.0 sec 220 MBytes 61.3 Mbits/sec
ipfw pipe 100 config bw 24Mbit/s queue 930
[ 3] 0.0-30.0 sec 82.5 MBytes 23.0 Mbits/sec
ipfw pipe 100 config bw 15Mbit/s queue 465
[ 3] 0.0-30.1 sec 51.8 MBytes 14.4 Mbits/sec
ipfw pipe 100 config bw 10Mbit/s queue 310
[ 3] 0.0-30.1 sec 34.6 MBytes 9.64 Mbits/sec
Надо будет дать 4% сверху, чтобы выйти на более/менее точные полосы для абонентов.
Всем отвечавшим - спс. Сделаем и мы свой маленький шаг в современный мир, поглядим как поведет себя система под нагрузкой в сравнении с 8.4
-
Конечно, до 2048
На всех мостах так, иначе gred нормально не настроить
-
чтобы не засорять - так думалось.
Если реально хотите помочь разобраться - сможете зайти удаленно ? Завтра могу навесить реальный адрес и подготовить логин/пароль в личку.
Доступ к стенду готов дать любому вызвавшемуся добровльцем :)
Но вообще, неужели ни у кого нет рабочего моста/шейпера на 11.2 / 12.0 ?
-
ipfw show
00100 2328 195552 pipe 100 ip from any to 10.10.10.0/24 out via ix0
00110 0 0 allow ip from any to 10.10.10.0/24 out via ix0
65535 23404 2769011 allow ip from any to any
-
сделал
sysctl net.inet.ip.forwarding=1
net.inet.ip.forwarding: 0 -> 1все также, трафик бесследно пропадает в dummynet :(
00100 1637 137508 pipe 100 ip from any to 10.10.10.0/24 out via ix0
00110 0 0 allow ip from any to 10.10.10.0/24 out via ix0
древний - не древний, а работает. Получить бы и здесь рабочий результат.
Я готов дать удаленный доступ умельцам - ради бога, покажите класс
-
то же самое будет если сделать просто ipfw pipe 100 config bw 15Mbit/s без доп. параметров.
По любому, пакет уходит в pipe и оттуда уже не возвращается - почему так ? :(
На 8.4 у меня штук 8 мостов шейпят народ, просто захотел проверить что изменилось за лет 6
Вот с моста на 8.4, через который шейпятся порядка 7 гиг трафика
sysctl net.inet.ip.forwarding
net.inet.ip.forwarding: 0 -
net.inet.ip.forwarding: 0 - вроде само собой ?
-
Опубликовано · Изменено пользователем Azamat · Жалоба на ответ
from any to 10.10.10.0/24 out via ix0 - это как раз произвольный трафик со стороны ix1 в сторону ix0 и наружу через ix0
все эти конструкции прекрасно работают на FB 8.4


2 шт Nexus 3064 ушли в ребут, утекла память ..
в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Опубликовано · Изменено пользователем Azamat · Жалоба на ответ
Всем доброго дня.
Если кто-то сталкивался, может подскажет с проблемой ?
Сегодня вдруг на 2 nexus 3064 часа за 3 утекла память до перезагрузки. Сначала подрос процессор с 20% до 40 % (что ниже порога извещения), потом коммутаторы ребутнулись.
Что бы могло вызвать такие глюки ?
Nex3064-mem leak