


HEDG
Активный участник-
Публикации
132 -
Зарегистрирован
-
Посещение
Все публикации пользователя HEDG
-
Добрый день всем Наговцам! При очередном чтении man ipfw обратил внимание, что в пайпах есть технология burst. burst size If the data to be sent exceeds the pipe's bandwidth limit (and the pipe was previously idle), up to size bytes of data are allowed to bypass the dummynet scheduler, and will be sent as fast as the physical link allows. Any additional data will be transmitted at the rate specified by the pipe bandwidth. The burst size depends on how long the pipe has been idle; the effec‐ tive burst size is calculated as follows: MAX( size , bw * pipe_idle_time). К сожалению в инете инфы не так много... (Например нашел статью О методах искусственного увеличения показаний). На первый взгяд все элементарно. Насколько понял, то при простое пайпа первый трафик указанный в burst не шейпится, после чего шейпинг происходит в обычном режиме. У меня, для каждого ip создается отдельный pipe в каждое из направлений (используется tablearg). Вот например задаем скрость пайпа в 1Mbit/s и burst 1Mbyte #ipfw pipe 9344 config burst 1M bw 1Mbit/s # ipfw pipe 9344 list 09344: 1.000 Mbit/s 0 ms burst 1048576 q140416 50 sl. 0 flows (1 buckets) sched 74880 weight 0 lmax 0 pri 0 droptail sched 74880 type FIFO flags 0x0 0 buckets 0 active При подобной настройке не происходит первоначального увеличения скорости... При дополнительно указанном queue: #ipfw pipe 9344 config burst 1M bw 1Mbit/s queue 800KB # ipfw pipe 9344 list 09344: 1.000 Mbit/s 0 ms burst 1048576 q140416 800 KB 0 flows (1 buckets) sched 74880 weight 0 lmax 0 pri 0 droptail sched 74880 type FIFO flags 0x0 0 buckets 0 active При такой настройке действительно происходит увеличение первоначальной скорости (стартует закачка с 200-250Kbyte/s) Какая вообще зависимость между burst и queue? Кто-то игрался с этими параметром? Есть ли какието "побочные" действия, кроме запланированого кратковременного увеличения скорости?
-
Добрый день всем Наговцам :)! Хочу перейти в ряды "тех кто делает бекапы". Прошу помочь определиться с системой бекапа, которая больше соответствует требованиям: 1. Собственно сама система бекапа, должна бекапить. 2. Уметь делать разные типы бекапов - Бекап всего диска(создание его образа) и бекап отдельных файлов; полные, инкриментные, дифф, в идеале еще и "на лету" как Box Backup. 3. Возможность восстановления "в течение получаса". Вижу схему следующим образом: - загрузка с флешки на любом компе с чистым HDD (если не чистый, то удаляются все разделы). - подтыкаем в сеть (запускаем скрипт для настройки сети) - Указываем с откуда и какой сервер восстанавливать + использование пароля или ключа для доступа. - После чего заливается и раскатывется последний снапшот системы и автоматом накатываются все последние изменения. Т.е. по факту система аналогичная как в acronis. 4. Простота использования при любом типе восстановления бекапов. 5. Надежность самой системы, отсутствие "узких мест" или хотябы уменьшения их влияния. 6. Возможность мониторинга системы бекапа. успех/крах/ошибки 7. Минимизировать занимаемое место, но практически без ущерба для скорости работы и восстановления 8. Система ротации бекапов. Уметь удалять старые данные после определенного периода (6-12мес.) 9. Правильное поведение системы при переполнении места в хранилище(ротация бекапов) 10. Безопасность передачи данных по сети. 11. Безопасное хранение данных. Шифрование или что-то подобное. Понятно, что это потенциальное узкое место. 12. Добавлять информацию о бекапах: откуда, тип бекапа, размер, дата создания и др. полезная инфа 13. Желательна какая-то веб морда для мониторинга и управления. 14. Основные ОС - FreeBSD. Неплохо также и кросспратформенность - возможность работы с Linux и Windows 16. Создания различных гибких схем, по времени и типам бекапов. 17. Возможность создания бекапа "по требованию", а не только по расписанию 18. Желательно отдельно уметь бекапить БД (Mysql, Postgresql), либо возможность "прикрутить" разные скрипы для этого. А ну и конечно OpenSource . Буду очень признателен, если Вы поделетесь своим мнением и опытом использования и внедрения подобных систем.
-
Повисание роутера BGP при падении роутера NAT
тему ответил в HEDG пользователя HEDG в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Опыт администрирования есть, знания тоже вроде некоторые имеются.. В данном случае нужен взгляд "со стороны", может кто-то хотя бы натолкнет на правильное направление... Внесу немного ясности.. Была проблема с блоком питания на NAT, соответственно отвалились все абоненты, но DMZ по идее должно было работать... В логах системы Aug 2 21:16:14 bgp kernel: net1: link state changed to DOWN В логах BGP есть следующее Aug 2 21:17:45 mart bgpd[1490]: SLOW THREAD: task bgp_scan_timer (104b560) ran for 7676ms (cpu time 587ms) Aug 2 21:19:06 bgp bgpd[1490]: SLOW THREAD: task bgp_scan_timer (104b560) ran for 29244ms (cpu time 588ms) Aug 2 21:19:06 bgp bgpd[1490]: Terminating on signal Aug 2 21:19:06 bgp bgpd[1490]: %NOTIFICATION: sent to neighbor x.x.x.x 6/3 (Cease/Peer Unconfigured) 0 bytes Aug 2 21:19:06 bgp bgpd[1490]: %NOTIFICATION: sent to neighbor xx.xx.xx.xx 6/3 (Cease/Peer Unconfigured) 0 bytes Aug 2 21:19:06 bgp bgpd[1490]: %NOTIFICATION: sent to neighbor xxx.xxx.xxx.xxx 6/3 (Cease/Peer Unconfigured) 0 bytes Aug 2 21:19:07 bgp bgpd[1490]: %ADJCHANGE: neighbor x.x.x.x Down Neighbor deleted Aug 2 21:19:08 bgp bgpd[1490]: %ADJCHANGE: neighbor xx.xx.xx.xx Down Neighbor deleted Aug 2 21:19:08 bgp bgpd[1490]: %ADJCHANGE: neighbor xxx.xxx.xxx.xxx Down Neighbor deleted Вот логи zebra 2011/08/02 21:17:43 ZEBRA: SLOW THREAD: task work_queue_run (210a4e40) ran for 12659ms (cpu time 0ms) 2011/08/02 21:17:57 ZEBRA: SLOW THREAD: task work_queue_run (210a4e40) ran for 8199ms (cpu time 0ms) 2011/08/02 21:18:10 ZEBRA: SLOW THREAD: task work_queue_run (210a4e40) ran for 12952ms (cpu time 0ms) 2011/08/02 21:18:22 ZEBRA: SLOW THREAD: task work_queue_run (210a4e40) ran for 6021ms (cpu time 0ms) 2011/08/02 21:18:41 ZEBRA: SLOW THREAD: task work_queue_run (210a4e40) ran for 10484ms (cpu time 0ms) 2011/08/02 21:18:55 ZEBRA: SLOW THREAD: task work_queue_run (210a4e40) ran for 13995ms (cpu time 0ms) 2011/08/02 21:57:44 ZEBRA: SLOW THREAD: task work_queue_run (210a4e40) ran for 2317764ms (cpu time 0ms) Роуты на сети которые обслуживает NAT прописаны в zebra. По логам видно, что упал демоны BGPd и zebra, непонятно почему... Для анонса сетей использовалась команда network, никаких redistribute не использовалось. Не понятно, почему происходил такой баг. В любом случае сервера NAT и BGP должны были видеть друг друга. Опять же непонятно почему сервера не видели друг друга после поднятия сервера NAT. Даже если учесть переполнение буфера сетевой, то он должен был освобождаться при Down Up интерфеса (делался программно, а также при выниманием патча). Не помогло. Сервера начинали видеть друг друга только при перезагрузке BGP. По логам большего накопать не удалось. -
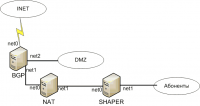
Доброго дня всем форумчанам. Есть следующая схема сети (cхемка ниже): На всех роутерах стоит FreeBSD 8.x. Сетевые карточки igb. Роутер BGP с 3-мя сетевыми net0 - интернет (подняты сессии BGP ), net1 - кабель напрямую в net0 NAT, net2 - зона DMZ. В качестве BGP работает quagga 0.99.17 Дальше соответственно идут сервер NAT (используется PF), за ним шейпер (ipfw pipe) и абоненты. В сети работает статика. Столкнулся со следующей проблемой: При падении сервера NAT, отваливается для внешки BGP сервер (зайти невозможно). DMZ зона также теряет связь с инетом (непонятно почему...). При поднятии сервера NAT, сервера NAT и BGP не видят друг друга по MAC. При этом сетевые линкуются нормально. Down затем Up интерфейсов не помогает. Приходится перезагружать и BGP сервер, тогда все начинает рабоать нормально. Подскажите пожалуйста, почему может происходить такая ситуация? Что не дает нормально работать BGP серверу? Если нужна еще какая-то инфа - говорите, постараюсь выложить... Собственно сама схемка
-
PF на FreeBSD под Xen
тему ответил в HEDG пользователя HEDG в Программное обеспечение, биллинг и *unix системы
Сетевая в физическом сервере под виртуальные серваки - Intel Desctop Pro 1000MT (сетевая нагрузка не большая, ее вполне хватает).Для управлению - другая... А На виртуально машине под FreeBSD светится виртуальная сетевая xn0 -
PF на FreeBSD под Xen
тему ответил в HEDG пользователя HEDG в Программное обеспечение, биллинг и *unix системы
Запустился на одном CPU, перекомпилил ядро. Ситуация не изменилась :( -
PF на FreeBSD под Xen
тему ответил в HEDG пользователя HEDG в Программное обеспечение, биллинг и *unix системы
Проца видна два last pid: 49410; load averages: 0.23, 0.33, 0.32 up 5+18:02:45 11:47:02 161 processes: 3 running, 143 sleeping, 15 waiting CPU 0: 0.0% user, 0.0% nice, 1.9% system, 1.5% interrupt, 96.6% idle CPU 1: 0.0% user, 0.0% nice, 1.1% system, 4.9% interrupt, 94.0% idle Mem: 350M Active, 44M Inact, 383M Wired, 16K Cache, 206M Free Swap: 1024M Total, 1024M Free PID USERNAME PRI NICE SIZE RES STATE C TIME WCPU COMMAND 11 root 171 ki31 0K 32K CPU0 0 92.4H 98.00% {idle: cpu0} 11 root 171 ki31 0K 32K RUN 1 92.4H 90.28% {idle: cpu1} 12 root -32 - 0K 240K WAIT 1 11:05 1.27% {swi4: clock} 12 root -52 - 0K 240K WAIT 0 45:55 0.59% {irq28: xenpci0} 12 root -32 - 0K 240K WAIT 1 11:30 0.20% {swi4: clock} Но не думаю, что проблема в этом. По крайней мере на другом серваке (не виртуальном), стоит двухядерный проц, на FreeBSD 8.1 с SMP и все работает нормально... -
Приветствую всех Наговцев! Поднят VPS. На одной из виртуалок есть проблема: При включении pf очень жестко тормозит система, даже консоль по ssh подвисает. Пробовал включать при pass all no state Флушал все через и делал отключение и включение pf pfctl -F all pfctl -d pfctl -e Ситуация не изменилась. Т.е. неважно есть ли какие то правила или нет, включение PF вводит систему в коматозное состояние. Родительская ОС - CentOS 5.5. Поднят Xen 3.4.3. Виртуальная машина (HWM) поднята FreeBSD 8.1-RELEASE-p2 #1 amd64 Ядро cpu HAMMER ident XENHVM # To statically compile in device wiring instead of /boot/device.hints #hints "GENERIC.hints" # Default places to look for devices. # Use the following to compile in values accessible to the kernel # through getenv() (or kenv(1) in userland). The format of the file # is 'variable=value', see kenv(1) # # env "GENERIC.env" makeoptions DEBUG=-g # Build kernel with gdb(1) debug symbols #makeoptions MODULES_OVERRIDE="" options SCHED_ULE # ULE scheduler options PREEMPTION # Enable kernel thread preemption options INET # InterNETworking options INET6 # IPv6 communications protocols options SCTP # Stream Control Transmission Protocol options FFS # Berkeley Fast Filesystem options SOFTUPDATES # Enable FFS soft updates support options UFS_ACL # Support for access control lists options UFS_DIRHASH # Improve performance on big directories options UFS_GJOURNAL # Enable gjournal-based UFS journaling options MD_ROOT # MD is a potential root device options NFSCLIENT # Network Filesystem Client options NFSSERVER # Network Filesystem Server options NFSLOCKD # Network Lock Manager options NFS_ROOT # NFS usable as /, requires NFSCLIENT options MSDOSFS # MSDOS Filesystem options CD9660 # ISO 9660 Filesystem options PROCFS # Process filesystem (requires PSEUDOFS) options PSEUDOFS # Pseudo-filesystem framework options GEOM_PART_GPT # GUID Partition Tables. options GEOM_LABEL # Provides labelization options COMPAT_43TTY # BSD 4.3 TTY compat (sgtty) options COMPAT_FREEBSD32 # Compatible with i386 binaries options COMPAT_FREEBSD4 # Compatible with FreeBSD4 options COMPAT_FREEBSD5 # Compatible with FreeBSD5 options COMPAT_FREEBSD6 # Compatible with FreeBSD6 options COMPAT_FREEBSD7 # Compatible with FreeBSD7 options SCSI_DELAY=5000 # Delay (in ms) before probing SCSI options KTRACE # ktrace(1) support options STACK # stack(9) support options SYSVSHM # SYSV-style shared memory options SYSVMSG # SYSV-style message queues options SYSVSEM # SYSV-style semaphores options _KPOSIX_PRIORITY_SCHEDULING # POSIX P1003_1B real-time extensions options KBD_INSTALL_CDEV # install a CDEV entry in /dev options HWPMC_HOOKS # Necessary kernel hooks for hwpmc(4) options AUDIT # Security event auditing #options KDTRACE_FRAME # Ensure frames are compiled in #options KDTRACE_HOOKS # Kernel DTrace hooks options NO_ADAPTIVE_MUTEXES options NO_ADAPTIVE_RWLOCKS #options IPFIREWALL # IPFW on #options IPFIREWALL_VERBOSE # Record recive log<---> #options IPFIREWALL_VERBOSE_LIMIT=10 # Limit line log<------> #options IPFIREWALL_FORWARD # Forward packets #options IPFIREWALL_DEFAULT_TO_ACCEPT # allow all on crash ipfw ### PF device pf device pflog ### FOR MPD options NETGRAPH options NETGRAPH_ETHER options NETGRAPH_SOCKET options NETGRAPH_TEE # Debugging for use in -current #options KDB # Enable kernel debugger support. #options DDB # Support DDB. #options GDB # Support remote GDB. #options INVARIANTS # Enable calls of extra sanity checking #options INVARIANT_SUPPORT # Extra sanity checks of internal structures, required by INVARIANTS #options WITNESS # Enable checks to detect deadlocks and cycles #options WITNESS_SKIPSPIN # Don't run witness on spinlocks for speed # Make an SMP-capable kernel by default options SMP # Symmetric MultiProcessor Kernel # CPU frequency control device cpufreq # Bus support. device acpi device pci # Floppy drives device fdc # Xen HVM support options XENHVM device xenpci # ATA and ATAPI devices device ata device atadisk # ATA disk drives device ataraid # ATA RAID drives device atapicd # ATAPI CDROM drives device atapifd # ATAPI floppy drives device atapist # ATAPI tape drives options ATA_STATIC_ID # Static device numbering # SCSI peripherals device scbus # SCSI bus (required for SCSI) device ch # SCSI media changers device da # Direct Access (disks) device sa # Sequential Access (tape etc) device cd # CD device pass # Passthrough device (direct SCSI access) device ses # SCSI Environmental Services (and SAF-TE) # atkbdc0 controls both the keyboard and the PS/2 mouse device atkbdc # AT keyboard controller device atkbd # AT keyboard device psm # PS/2 mouse device kbdmux # keyboard multiplexer device vga # VGA video card driver device splash # Splash screen and screen saver support # syscons is the default console driver, resembling an SCO console device sc device agp # support several AGP chipsets # Serial (COM) ports device uart # Generic UART driver # PCI Ethernet NICs that use the common MII bus controller code. # NOTE: Be sure to keep the 'device miibus' line in order to use these NICs! device miibus # MII bus support device re # RealTek 8139C+/8169/8169S/8110S # Pseudo devices. device loop # Network loopback device random # Entropy device device ether # Ethernet support device tun # Packet tunnel. device pty # BSD-style compatibility pseudo ttys device md # Memory "disks" device gif # IPv6 and IPv4 tunneling device faith # IPv6-to-IPv4 relaying (translation) device firmware # firmware assist module # The `bpf' device enables the Berkeley Packet Filter. # Be aware of the administrative consequences of enabling this! # Note that 'bpf' is required for DHCP. device bpf # Berkeley packet filter loader.conf vfs.root.mountfrom="zfs:tank0" zfs_load="YES" hw.clflush_disable="2" Других изменений вроде не делалось.. Если что-то еще нужно выложить - говорите... P.S. Заранее спасибо за помощь!!
-
Доступ к управляемым свитчам
тему ответил в HEDG пользователя HEDG в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Я ж не против. Наоборот огромное спасибо всем отозвавшимся!!! Для этого тему и создавал! Просто я указываю, что в каждой схеме есть свои + и - ... Возможно кто-то подскажет более совершенные варианты... -
Доступ к управляемым свитчам
тему ответил в HEDG пользователя HEDG в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Почему неправильно? Ну стоит у вас в райончике 50 свичей - выделите им отдельный управляющий влан, на который повесите /24 и ипы согласно номерам домов (или близко к ним). Другая /24 (или /23 или /22, дело вкуса) - уже другой район. Ну как-то так. И не запутаетесь. Я наверно один такой жахнутый, но иногда встречается и отдельный управляющий влан на 1 дом (особенности применения 3028). Я имел ввиду, что 254 свитча в одной /24 - это как-то перебор не люблю, когда в одном сегменте сети находится слишком много конечных устройств... Тем более устройства с разных уровней - ядро и доступ Что будет с такой сеткой если Свитч глюканул и фактически устраивает ДОС ? Что будет если какая-то падла сделала кольцо в свитче ? -
Доступ к управляемым свитчам
тему ответил в HEDG пользователя HEDG в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Влан на дом это конечно замечательно.... По факту это повышает общую безопасность и стабильность,но усложняет управление. В случае чего не сильно усложняет устранение проблем в аварийном режиме, особенно когда придется полазить с ноутом по домам (о чем уже писали выше). А если учесть, что желательно иметь влан для абонентов на дом + еще один влан на дом для управления конкретным свитчем... Получается некоторое нагромождение... -
Доступ к управляемым свитчам
тему ответил в HEDG пользователя HEDG в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Я так понимаю, наилучшим вариантом будет отдельный тегированный влан для управления свитчами. Т.е. получается что на все порты провешивается дополнительный тегированный влан, на который и вешается ип доступа. и Дальше этот влан можно вывести уже туда, куда необходимо... Преимущества по безопасности очевидны.... Вопрос менеджмента. Заводить на каждый свитч /30, как-то неудобно при наличии нескольких сотен свитчей... Вешать сплошняком в /24 тоже не правильно... Как вариант - Делать какое-то географическое разбиение и разбиение по умолчанию... Я правильно понимаю? Есть еще какие-то правильные варианты? -
Доступ к управляемым свитчам
тему ответил в HEDG пользователя HEDG в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
судя по тому, что автор темы после своего поста в тему больше не заглядывает - уже :D Я тут :)Просто есть области сети, где не используются серые ip из идеологических соображений, т.к. их там быть не должно... Вот и борется желание сделать все правильно (согласно идеалогии) и жаба которая говорит, что нельзя столько ip тратить. Плюс паранойя борется за безопасность... Вот и думаю как это лучше все сделать... Да чужой опыт не повредит.. -
Доброго времени суток всем НАГовцам! Встал вопрос, каким образом будет правильно назначать ип адреса для управляемых свитчей (которые не участвуют в маршрутизации трафика). Свитчи можно разделить на четыре глобальные группы: - уровень агрегации (доступа) абонентов - свитчи ядра сети - внешние свитчи(у вышестоящих провайдеров) - свитчи у клиентов, которые берут интернет. Требования: - Учесть, что сеть не использует VPN. - минимальное использование реальных адресов - область, где используются реальные ip (бгп, свитчи у аплинков, свитчи у клиентов) не должны иметь серых ip адресов - Безопасность. Доступ только с определенных подсетей (ip адресов). Желательно, чтоб ни абоненты ни клиенты не могли получить доступ (причем на уровне маршрутизации, т.к. не на всех свитчах есть возможность ограничить доступ на свитче) - схема доступа к свитчам должна относительно легко меняться при необходимости - Легкая в понимании, реализации и запоминании схема управления и распределения ip адресов свитчей. Итак поделюсь своими соображениями на данный счет: - Уровень агрегации абонентов Зависит конечно от распределения серого адресного пространства. Очень часто встречается подсеть на дом (у меня аналогично). В таком случае можно например зарезервировать часть начальных адресов подсети под свои нужды(например первые /27 или /28). На свитче прописывается ип из этой подсети с маской /28. А на роутере x.x.x.1/24 . Соответственно роутер видит и абонов и свитч, а абоны напрямую не могут получить доступ к свитчу (конечно если абон не поменяет себя адрес на входящий в этот диапазон). Дополнительно можно убрать роут по умолчанию и прописать только несколько нужных роутов. Либо зарезать доступ фаерволом на смомо роутере Есть конечно вариант с выделением отдельного влана Свитчи ядра сети можно прописать ип из той области, которую обслуживает данный свитч. Роут по умолчанию убирается. Прописываются статикой пару нужных, для доступа на него. ма Внешние свитчи (у вышестоящих провайдеров) Выделяется подсеть /30 из рельников и провешивается на BGP роутере. С маршрутами можно поступить аналогично + зарезать доступ к свитче на роутере с BGP. Cвитчи у клиентов, которые берут интернет Даже не знаю как правильно, выдавать отдельно /30 из реальников - слишком большой расход реальников... Выдавать серые подсети нехорошо, т.к. роутер с BGP не должен иметь серых подсетей (внутренняя политика насчет подсетей). Если клиенту выдается например подсеть /29 и больше, то можно конечно забрать один ип под свитч, но это тоже не самое красивое решение. К тому же в этом случае клиентам прийдется выдавать минимум /29. Поделитесь, у кого какие соображения на данный счет, у кого и как реализовано управление и доступ к свичам? Каким образом назначаете ип адреса для управления свитчами в разных частях сети (разного назначения)? Что по этому поводу рекомендует Cisco и другие?
-
Доброго времени суток всем Наговцам! На одном из интерфейсов приходит вот такой трафик 21:42:34.909812 dc:7b:94:08:bb:16 (oui Unknown) > 01:00:0c:cc:cc:cd (oui Unknown), 802.3, length 64: LLC, dsap SNAP (0xaa) Individual, ssap SNAP (0xaa) Command, ctrl 0x03: oui Cisco (0x00000c), pid Unknown (0x010b): Unnumbered, ui, Flags [Command], length 50 21:42:36.917328 dc:7b:94:08:bb:16 (oui Unknown) > 01:00:0c:cc:cc:cd (oui Unknown), 802.3, length 64: LLC, dsap SNAP (0xaa) Individual, ssap SNAP (0xaa) Command, ctrl 0x03: oui Cisco (0x00000c), pid Unknown (0x010b): Unnumbered, ui, Flags [Command], length 50 21:42:38.920532 dc:7b:94:08:bb:16 (oui Unknown) > 01:00:0c:cc:cc:cd (oui Unknown), 802.3, length 64: LLC, dsap SNAP (0xaa) Individual, ssap SNAP (0xaa) Command, ctrl 0x03: oui Cisco (0x00000c), pid Unknown (0x010b): Unnumbered, ui, Flags [Command], length 50 21:42:40.923270 dc:7b:94:08:bb:16 (oui Unknown) > 01:00:0c:cc:cc:cd (oui Unknown), 802.3, length 64: LLC, dsap SNAP (0xaa) Individual, ssap SNAP (0xaa) Command, ctrl 0x03: oui Cisco (0x00000c), pid Unknown (0x010b): Unnumbered, ui, Flags [Command], length 50 21:42:42.926246 dc:7b:94:08:bb:16 (oui Unknown) > 01:00:0c:cc:cc:cd (oui Unknown), 802.3, length 64: LLC, dsap SNAP (0xaa) Individual, ssap SNAP (0xaa) Command, ctrl 0x03: oui Cisco (0x00000c), pid Unknown (0x010b): Unnumbered, ui, Flags [Command], length 50 21:42:44.929815 dc:7b:94:08:bb:16 (oui Unknown) > 01:00:0c:cc:cc:cd (oui Unknown), 802.3, length 64: LLC, dsap SNAP (0xaa) Individual, ssap SNAP (0xaa) Command, ctrl 0x03: oui Cisco (0x00000c), pid Unknown (0x010b): Unnumbered, ui, Flags [Command], length 50 Встал вопрос, можно ли во FreeBSD запретить весь трафик по протоколу SNAP ? Можно ли его заблокировать на Cisco 29xx ? Где может использоваться этот протокол в современных реалиях? P.S. заранее спасибо за помощь.
-
Посоветуйте маршрутизатор bgp
тему ответил в rush пользователя HEDG в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Боевой тазик c FreeBSD + quagga + ipfw + несколько небольших сервисов Intel® Core2 Duo CPU E4600 @ 2.40GHz DDR2 2GB 4-x портовая сетевая Intel PCI-Ex4 Молотит трафик ~ 300Мбит/с (по внешнему интерфейсу full duplex) Загрузка CPU ~50% Принимает 3 full view + IX + пиринги. В момент приема всех префиксов примерно на 1 мин проц уходит в полку. P.S. при отсутствии необходимых финансов, вполне достойный выход, особых нареканий не имею. Просто брать нормальную связку проц+ сетевые. -
6-ти значные АС
тему ответил в HEDG пользователя HEDG в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Спасибо! -
6-ти значные АС
тему ответил в HEDG пользователя HEDG в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Т.е. получается, что даже у магистральщиков не все оборудование поддерживает 32-битные АС ? -
Доброго времени суток всем Наговцам. Работаю с BGP уже достаточно продолжительное время. Столкнулся с шестизначными номерами AS. Как обычно решил просмотреть по Looking Glass (http://lg.rusnet.ru/), роут на свою АС(197131). BGP routing table entry for 195.54.52.0/23 Paths: (1 available, best #1, table Default-IP-Routing-Table) Advertised to non peer-group peers: 194.85.4.4 194.85.4.9 194.85.4.12 194.85.4.13 194.85.4.14 194.85.4.15 194.85.4.16 194.85.4.25 3216 12883 43586 23456 194.186.155.137 from 194.186.155.137 (194.67.0.185) Origin IGP, localpref 600, valid, external, best Community: 3216:2001 (Full transit customer and own networks) 3216:4461 3216:5900 (Do not advertise to any INTERNATIONAL peer) 3277:3216 3277:65100 12883:1 12883:101 12883:11044 Last update: Tue Nov 2 01:27:43 2010 Почему мне вместо пути на мою АС выдается путь 3216 12883 43586 23456? Это на всех шестизначных АС? Аналогичная ситуация и в других lg. При этом пинги бегают нормально. % Information related to 'AS23456' aut-num: AS23456 as-name: RESERVED-AS descr: assigned by IANA http://www.iana.org/assignments/as-numbers descr: see http://www.ietf.org/rfc/rfc4893.txt org: ORG-IANA1-RIPE admin-c: RFC1918-RIPE tech-c: RFC1918-RIPE mnt-by: RIPE-NCC-HM-MNT source: RIPE # Filtered organisation: ORG-IANA1-RIPE org-name: Internet Assigned Numbers Authority org-type: IANA address: see http://www.iana.org remarks: The IANA allocates IP addresses and AS number blocks to RIRs remarks: see http://www.iana.org/ipaddress/ip-addresses.htm remarks: and http://www.iana.org/assignments/as-numbers admin-c: IANA1-RIPE tech-c: IANA1-RIPE mnt-ref: RIPE-NCC-HM-MNT mnt-by: RIPE-NCC-HM-MNT source: RIPE # Filtered role: RFC1918 Role address: Singel 258 address: 1016 AB Amsterdam address: The Netherlands remarks: trouble: See http://www.ripe.net/db/rfc1918.html admin-c: RFC1918-RIPE tech-c: RFC1918-RIPE nic-hdl: RFC1918-RIPE mnt-by: RFC1918-MNT source: RIPE # Filtered
-
Беспроводная связь телевидения.
тему ответил в HEDG пользователя HEDG в Беспроводные сети Wi-Fi, 3G/LTE/5G, LoRa...
Да, прошу прощения за неточность. Имелся ввиду Ubiquiti Bullet M, с хорошей антенной, при наличии прямой видимости и у с учетом зоны Френеля, Расстояние в 10км должно быть доступным для такого вещания, т.к там поток не большой из-за маленького разрешения. К сожалению на практике доказать не могу по причине отсутствия оборудования. P.S. соблюдение условий для нормальной передачи данных является достаточно критичным, поэтому данная схема может использоваться в небольших телекомпаниях временно или от безысходности.... -
Беспроводная связь телевидения.
тему ответил в HEDG пользователя HEDG в Беспроводные сети Wi-Fi, 3G/LTE/5G, LoRa...
Задачу решил, теми средствами которые были выделены... Кратко опишу как ее решил(мало ли кто еще будет заниматься таким извратом) Учитывая что камеры снимают с разрешением 720*576, то поток не такой большой. Схема следующая: Транслирующая сторона - DV камера по FireWare подрублена к ноуту. На ноуте запущен VLC который делает захват видео с камеры, кодирует его в H264 (при других кодаках картинка рассыпется) и по http транслирует его с использованием наноса2 Приемная сторона - Высотка, на крыше нанос2 втыкнут в ноут на принимающей стороне.Делаем захват НТТP потока и выдаем видео на второй монитор (устройство подключенное через S-Video) а звук через вход для наушиков. Примечание: ноут на транслирующей стороне должен быть достаточно мощным (был Dell С двухядерным процем по 1,8, оба ядра в 100%). Есть задержка примернов 2,8с от расстояния практически не зависит. Данная схема гарантированно работала на расстоянии 2км (дальше просто не тестировали). На прямой видимости работает нормально. Думаю, если использовать наносы М c качественными антеннами и камерой, котрая сразу пишет в H264, то такая схема вполне жизнеспособна на расстоянии до 10км при условии соблюдения прямой видимости и с учетом первой зоны Френеля . -
Беспроводная связь телевидения.
тему ответил в HEDG пользователя HEDG в Беспроводные сети Wi-Fi, 3G/LTE/5G, LoRa...
Будет подключаться Panasonic AG-DVX100BE или Sony DCR-VX2100E.P.S. может кто-то подскажет проверенное ПО, которое может поток от камеры направить в сеть (возможно предварительно обработав) -
Беспроводная связь телевидения.
тему ответил в HEDG пользователя HEDG в Беспроводные сети Wi-Fi, 3G/LTE/5G, LoRa...
Было бы интересно провести сравнительное тестирование различных технологий и оборудования на практике. P.S. а пока придется поднимать на том, что имеется, а дальше уже решать... -
Беспроводная связь телевидения.
тему ответил в HEDG пользователя HEDG в Беспроводные сети Wi-Fi, 3G/LTE/5G, LoRa...
В крайнем случае можно поставить Wi-Fi повыше (просто удлинив витую пару между ноутом и передатчиком).При этом остается возможность снимать с правильного ракурса, хотя и добавляет лишние хлопоты... Насчет камеры, узнаю... В крайнем случае, будут покупать ip video server или видео камеру со встроенным. -
Беспроводная связь телевидения.
тему ответил в HEDG пользователя HEDG в Беспроводные сети Wi-Fi, 3G/LTE/5G, LoRa...
Очень заинтересовало, расскажите пожалуйста поподробнее (мысль о подобной схеме приходила, но просчитать ее еще не успел). Какое оборудование стояло на телестанции, у оператора, на остальных БС? Какое в среднем расстояние было между БС? Какие антенны использовали? Если не сложно, опишите или набросайте пожалуйста принципиальную схемку. Какова примерная стоимость проекта по оборудованию в Вашем случае? Возникали какие то дополнительные сложности (кроме видимости)? У операторов были камеры с сетью или использовалось еще какое-то оборудование (ноутбуки, ip video server и др.) или специализированное ПО на них?
