


napTu
Пользователи-
Публикации
29 -
Зарегистрирован
-
Посещение
Все публикации пользователя napTu
-
Приказ 221 Сведения в Роскомнадзор - Принято
тему ответил в Связной (С) пользователя napTu в У нага
большой поклон! Нельзя что ли и им также, голову не морочить, а просто показать пример. -
"Флудят" роутеры TP-Link
тему ответил в Trueno пользователя napTu в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Мы с этим уже лет 7 живём. Роутер виснет и выставляет на внешнем интерфейсе флаг FlowControl, по которому свич становится в паузу. Варианты решения -управляемый свич, у них по умолчанию flowcontrol выключен; -в старых чипсетах ic+, на которых шли ранее мыльницы,есть вывод, которым управляется flow control, отрываем, садим на землю и радуемся - бегать отключать и обзванивать чтобы ребутали роутеры -
Настройка Терминала Абонетского (ONU) BDCOM P1702-4F-02
тему ответил в line59 пользователя napTu в Оборудование BDCOM
Нужно выключить на P1702-4G изолирование медных портов. Делаю switch_config_epon0/1:1#no epon onu port-protect Ничего не меняется, одно устройство даже не видит мак другого, а другое иногда видит мак, но ничего кроме этого больше не ходит. По трейсу только loop protect пакеты от onu и то что приходит с аплинка. Подскажите, куда копать? -
netflow sensor linux/freebsd
тему ответил в artplanet пользователя napTu в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
нужна freebsd+netflow v9 с расширением NEL (NAT events extension ) нашел только упоминание https://lists.freebsd.org/pipermail/freebsd-net/2013-October/036993.html -
FreeBSD + 10 Gbit ixgbe + dummynet
тему ответил в John_obn пользователя napTu в Программное обеспечение, биллинг и *unix системы
удалось снизить нагрузку dummynet на 20% за счет установки параметра pipe burst на 20 мегабайт -
Проблема с сфп-портами Dlink DGS-3100-24TG
тему ответил в Laa пользователя napTu в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Была подобная проблема, но правда помогало передергивание сфп или port state disable/enable. В первый раз переставили на другие порты и работали дальше без проблем, пометив предыдущие "плохими", потом, со временем пришлось занять и "плохие" и они работают до сих пор нормально. Во второй раз на любых портах гас 20км модуль, в другом свиче нормально работает, а в этом гаснет. Замена модуля на того же производителя и той-же дистанции помогла. Ревизия A2. -
Новые дрова от Яндеха
тему ответил в Elisium пользователя napTu в Программное обеспечение, биллинг и *unix системы
я смутно представляю обработку пакета, но из того что вычитал про HK_QUEUE, это что дальнейшая обработка пакета производится на базе подсистемы netisr. И тут теряется смысл уходить из ISR в netgraph чтобы затем вернуться в ISR. Пока что вроде собрались yandex драйвера под 9.1release с небольшой правкой мелкой наждачкой: в /usr/src/sys/dev/e1000/e1000_osdep.h закоментил строки 76,78,99 (на которые была ругань) и в /usr/src/sys/modules/em/Makefile убрал e1000_i210.c ... собирал только em драйвер, да и тот похоже не заработал, нет опций rx_queue в sysctl... Полная сборка ядра не идет, ругается на igb ... сетевушки PCI на новособранной тестовой машинке оказались, а на них только legacy em драйвер, который яндексами не поддерживается... -
FreeBSD 9.0 + em
тему ответил в 2ihi пользователя napTu в Программное обеспечение, биллинг и *unix системы
похожую ситуацию давно наблюдаю на 8.1 с яндекс дровами, когда перезагрузка раза в два снижает пиковую нагрузку CPU. Были идеи что замусориваются таблицы в ipfw или еще какие буфера. А то что перекос входа-выхода разных интерфейсов роутера, так это действительно быстрее всего разный путь обработки пакета в ipfw -
Новые дрова от Яндеха
тему ответил в Elisium пользователя napTu в Программное обеспечение, биллинг и *unix системы
а есть смысл ? если да , то немножко ближе к реализации кто то может натолкнуть? Например если принимаемый трафик направить в ng_onw2many, а затем с каждого many вернуть в ядро, этого будет достаточно, или необходимы еще какие либо ноды для организации очереди? -
3526
тему ответил в zlolotus пользователя napTu в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
естественно речь о 100мбит портах. я не понимаю, des-3028 и cisco2950 дают в полке 12800кбайт/с, почему 3526 не дает? -
3526
тему ответил в zlolotus пользователя napTu в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
раз уж 3536, то спрошу здесь Заметил что на моем 3526 максимальная скорость по show packet ports составляет 9523840 байт в сек, упирается в это значение и растут пинги, делю на 1024, получается 9300,625 кбайт/сек, или 74405кбит/с, или 72.66 мбит/с Возникает вопрос - куда же деваются оставшиеся 27.33 мбит полосы порта? Перекопал все настройки, никаких ограничений нет, ни в hardware , ни в cpu, практически все фичи выключены, свич сброшен был перед продажей. Работают только два access_profile на tcp445 deny и udp68 deny. Если, например, ставить config bandwidth_control 1-24 rx_rate 99 tx_rate 99 то всё равно маскимум 9523840 байт в сек. А как у вас? -
управляемый - циска2950. раздача через основной шлюз. пакеты в ответе не дробленные, так и идут по 1300-1500 байт. в запросах все пакеты короткие, но и аплинка особого нет. мультикаст шторм? и куда он девается при закрытии доступа в инет?
-
У нас тепло, +5 - +15, иногда сыро, но зависимости нет. есть, смотрел, udp,tcp обмен торрента, ничего лишнего или необычного, искал какие либо маркеры пакетов, но возможно они в центре уже отфильтрованы. input flow-control is unsupported output flow-control is unsupported
-
Может кто то посоветует по сабжу? Ситуация периодически наблюдается на нескольких сегментах сети. Сеть построена на управляемом свиче в середине и оптическими 100мбит выносами на конверторах, затем идут по частному сектору 100м отрезки на неуправляемых свичах. При включении одним из клиентов какого то хитрого торрента возрастают пинги в пределах всего сегмента после оптики, даже в другую ветку от оптики. При запрещении на роутере ip трафика от этого клиента пинги становятся 1-2мс, если же блокировать трафик tcp или udp по раздельности, то пинги кратковременно уменьшаются до 10-20мс, а затем снова возрастают до 30-60мс. От клиента поступает при этом примерно 50 очередей и низкий upload, при этом download к нему около 10мбит. Общий download на сегмент 20-30мбит Как вариант, пакеты маркируются высоким приоритетом QoS? Не нашел никакой информации по этому поводу, неизвестно, понимают ли неуправляемые свичи (или конверторы) маркеры qos и может ли торрент маркировать так пакеты.
-
Винт SATA 300Гиг, swap раздел отдельный, остальные разделы совмещены на руте. Nov 21 00:23:21 icenet savecore: reboot after panic: page fault Nov 21 00:23:21 icenet savecore: writing core to vmcore.1 Nov 21 01:57:22 icenet kernel: em1: link state changed to DOWN Nov 21 01:57:22 icenet kernel: em1: permanently promiscuous mode enabled Кто может подсказать?
-
cisco 2950 в центре c одним сегментом разделенным на несколько vlan
тему ответил в napTu пользователя napTu в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
ну типа так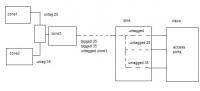
-
ух как всё запущено... после замены машины на двуядерную нагрузка по taskq процессам выравнялась странно то что драйвер кушал на прием в два раза больше CPU, чем на передачу
-
Имеется роутер freeBSD8 , установлена двухголовая сетевуха Intel PRO1000, на роутере крутятся ipfw_NAT и dummynet шейпер, проблема в том что нагрузка CPU не внешнем интерфейса в два раза выше чем на внутреннем CPU: 0.0% user, 0.0% nice, 38.5% system, 1.5% interrupt, 60.0% idle Mem: 13M Active, 73M Inact, 130M Wired, 100K Cache, 110M Buf, 768M Free Swap: 499M Total, 499M Free PID USERNAME PRI NICE SIZE RES STATE TIME WCPU COMMAND 11 root 171 ki31 0K 8K RUN 719.7H 75.88% idle 0 root -68 0 0K 72K - 250.8H 19.19% {em1 taskq} 0 root -68 0 0K 72K - 140.3H 7.08% {em0 taskq} 12 root -32 - 0K 152K WAIT 16.9H 0.39% {swi4: clock} - это утром, когда нагрузки нет, в часы пик всё совсем плачевно, на роутер по ssh зайти невозможно. # netstat -I em0 1 input (em0) output packets errs idrops bytes packets errs bytes colls 4581 0 0 1963289 8970 0 11783169 0 2750 0 0 1546138 3936 0 4542593 0 3646 0 0 1542227 7645 0 9602153 0 5698 0 0 1674778 12439 0 15911144 0 4211 0 0 1532071 9564 0 11906136 0 3793 0 0 1512754 8095 0 10265014 0 4955 0 0 1732655 11360 0 14124697 0 ^C # netstat -I em1 1 input (em1) output packets errs idrops bytes packets errs bytes colls 8794 0 0 11249858 3362 0 975056 0 7600 0 0 9997996 3077 0 1001101 0 10414 0 0 13646838 4013 0 1003573 0 10120 0 0 12928187 3923 0 1057064 0 10329 0 0 13476388 4049 0 1107544 0 9571 0 0 12497571 3726 0 965102 0 7356 0 0 9980667 3295 0 1049251 0 pps соответственно перекошен с большей частью по приему через внешний интерфейс em1. Кто то сталкивался, что может вызывать перекос нагрузки CPU, преимущественно входящий трафик или NAT на этом интерфейсе?
-
cisco 2950 в центре c одним сегментом разделенным на несколько vlan
тему ответил в napTu пользователя napTu в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Включил на портах принимающих растегированный трафик Protected Port режим. Вроде работает нормально пока... Возможно циска что то рассылает в эти порты, что не подвержено тегированию и отсюда проблемы... -
Есть циска 2950 в центре сети, есть длинный сегмент в частном секторе, который в конце своего пути делится еще на два больших сегмента. На сегменте наблюдаются периодические проблемы с потерями и длинными пингами до 100мс в любой точке, даже самой близкой к началу. Циска успешно фильтрует эту ситуацию для других своих портов. При отключении в точке разветвления одного из подсегментов, ситуация с потерями нормализуется. В точке разветвления есть возможность использовать железку умеющую VLAN. Не хочется тянуть выделенные линки для самых дальних сегментов. Хочется логически разделить эти сегменты чтобы их свитчинг производился с помощью циски. Теперь самое интересное извращение. Ближний сегмент оставляем без VLAN, а дальние два тегируем на vlan25 и 35. Принимаем всю эту кашу в порт циски, и выводим untagged 25 и 35 в отдельные access порты циски. Берем два патчкорда, соединяем эти access порты с обычными портами vlan1. Не поверите, всё работает, но через некоторые время начинаю идти жалобы, некоторые абоненты видятся только по arp ping, видимо где то возникают ошибки свитчинга. Операция по разделению была опробована также на dlink свиче, проблема осталась та же. Вот как выглядит мак таблица на свиче, выполняющем разделение, для одного мака в ближней нетегированной зоне. Command: show fdb mac_address 00-21-85-18-E8-41 VID VLAN Name MAC Address Port Type ---- ---------------- ----------------- ---- --------- 1 vl1 00-21-85-18-E8-41 1 Dynamic 25 vl25 00-21-85-18-E8-41 3 Dynamic 35 vl35 00-21-85-18-E8-41 4 Dynamic Total Entries : 3 Первый порт принимает весь трафик, второй отдает то что принято untagged, третий то что принято с тегом 25, четвертый - с тегом 35. На первом порту есть этот мак изначально, далее, через второй порт отдается на обычный свитчинг, с которого возвращается трафик на порты 3 и 4 и они обучаются этому маку т.к. являются участниками отдельных vlan Вроде всё правильно в логике, не понятно откуда проблема берется.
-
Новые дрова от Яндеха
тему ответил в Elisium пользователя napTu в Программное обеспечение, биллинг и *unix системы
опять паник, опять новоскомпиленные дрова не поднялись, что еще им нужно? -
Новые дрова от Яндеха
тему ответил в Elisium пользователя napTu в Программное обеспечение, биллинг и *unix системы
на 8.1R под PT DUAL собирал 6.9.14, if_lem подставлял из родных драйверов, периодически падает, от нагрузки не зависит, в выводе дампа есть указатели на драйвер, но не пойму точно из-за драйверов ли? current process = 12 (swi4: clock) trap number = 12 panic: page fault ... #0 doadump () at pcpu.h:246 246 __asm __volatile("movl %%fs:0,%0" : "=r" (td)); (kgdb) backtrace #0 doadump () at pcpu.h:246 #1 0xc088fa57 in boot (howto=260) at /usr/src/sys/kern/kern_shutdown.c:416 #2 0xc088fcb9 in panic (fmt=Variable "fmt" is not available. ) at /usr/src/sys/kern/kern_shutdown.c:590 #3 0xc0bea48c in trap_fatal (frame=0xc556463c, eva=12) at /usr/src/sys/i386/i386/trap.c:938 #4 0xc0bea710 in trap_pfault (frame=0xc556463c, usermode=0, eva=12) at /usr/src/sys/i386/i386/trap.c:851 #5 0xc0beb055 in trap (frame=0xc556463c) at /usr/src/sys/i386/i386/trap.c:533 #6 0xc0bcd16b in calltrap () at /usr/src/sys/i386/i386/exception.s:165 #7 0xc1014e42 in em_xmit (adapter=0xc5be4000, m_headp=Variable "m_headp" is not available. ) at /usr/src/sys/modules/em/../../dev/e1000/if_em.c:3895 #8 0xc1017dd8 in em_mq_start_locked (ifp=0xc5bbb000, m=0xc6921700) at /usr/src/sys/modules/em/../../dev/e1000/if_em.c:1119 #9 0xc10182cc in em_mq_start (ifp=0xc5bbb000, m=0xc6921700) at /usr/src/sys/modules/em/../../dev/e1000/if_em.c:1178 #10 0xc094629a in vlan_start (ifp=0xc632f400) at /usr/src/sys/net/if_vlan.c:925 #11 0xc0934162 in if_start (ifp=0xc632f400) at /usr/src/sys/net/if.c:3345 #12 0xc093810b in if_transmit (ifp=0xc632f400, m=0xc6921700) at /usr/src/sys/net/if.c:3357 #13 0xc093ce30 in ether_output_frame (ifp=0xc632f400, m=0xc6921700) at /usr/src/sys/net/if_ethersubr.c:452 #14 0xc093d84e in ether_output (ifp=0xc632f400, m=0xc6921700, dst=0xcc8d4c50, ro=0xc5564b18) at /usr/src/sys/net/if_ethersubr.c:423 #15 0xc09b6738 in ip_output (m=0xc731b500, opt=0x0, ro=0xc5564b18, flags=Variable "flags" is not available. ) at /usr/src/sys/netinet/ip_output.c:634 #16 0xc0a1e70f in tcp_output (tp=0xc8daf768) at /usr/src/sys/netinet/tcp_output.c:1190 #17 0xc0a26f86 in tcp_timer_rexmt (xtp=0xc8daf768) at /usr/src/sys/netinet/tcp_timer.c:581 #18 0xc08a2e5c in softclock (arg=0xc0df53e0) at /usr/src/sys/kern/kern_timeout.c:430 #19 0xc08661db in intr_event_execute_handlers (p=0xc59557f8, ie=0xc599ad00) at /usr/src/sys/kern/kern_intr.c:1220 #20 0xc08678eb in ithread_loop (arg=0xc5954230) at /usr/src/sys/kern/kern_intr.c:1233 #21 0xc0863f11 in fork_exit (callout=0xc0867880 <ithread_loop>, arg=0xc5954230, frame=0xc5564d38) at /usr/src/sys/kern/kern_fork.c:844 #22 0xc0bcd1e0 in fork_trampoline () at /usr/src/sys/i386/i386/exception.s:270 (kgdb) собрал теперь e1000 с надеждой что поможет, собралось без вопросов. Однако не загрузились новые драйвера e1000-7.0.5... Выдали kernel: link_elf: symbol e1000_init_mbx_ops_generic undefined Пока откатил на версию em-6.9.14 Как понял из описания подобных проблем - или нужно пересобирать всё ядро, или добавить недостающие зависимости типа MODULE_DEPEND(xxxx, xxxx, 1, 1, 1); Блин, торможу, выше всё написано по линковке 7.0.5 на 8.1 -
а 3comы имеют свойство падать?
-
ipfw3 pipe больше 24Мбит
тему ответил в nicol@s пользователя napTu в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
Ха, прикол, по моим наблюдениям восьмерка не реагирует на отключение net.inet.ip.dummynet.io_fast увеличением нагрузки на проц., а возможно даже реагирует падением нагрузки ))) Так что жизнь вполне налаживается, осталось перевести основной роутер с семерки. Однако второй описанный мной глюк dummynet не уходит Что происходит в общем то повсеместно. -
ipfw3 pipe больше 24Мбит
тему ответил в nicol@s пользователя napTu в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
несколько месяцев как столкнулся с этой проблемой, она действительно присутствует везде(во всех версиях фри), просто не у всех net.inet.ip.dummynet.io_fast=1, как только ставишь в 0, все проблемы уходят. Открыл соответствующий pr http://www.freebsd.org/cgi/query-pr.cgi?pr=kern/147245 , где описано две проблемы, вышеуказанная и еще одно пропускание трафика, когда торент качает с разных источников на один и тотже адрес и порт. Без net.inet.ip.dummynet.io_fast=1 естественно жить невозможно. Испытал ng_car - грузит систему сильнее раза в два, сделал коммент тут http://www.opennet.ru/base/net/ng_car_ipfw.txt.html PF ALTQ не подходит, т.к. не умеет простым образом нарезать очень много полос динамически, или хотябы изменением конфигурации с прямым указанием (нужно перезапускать весь конфиг). Спасибо что хоть подсказали способ с HZ= Интересная цитата ML lugi , но до конца не понятно. Получается что при 12000Кбит/c, мы, с 1/1000сек тиками можем обрабатывать 12000/1000 = 12Кбит. за один тик = 1,5КБайта за тик, что есть максимальный размер пакета. Что это значит я не знаю, но истина где то тут. Нифига не пойму откуда разговор о скоростях 400-1000мбит, може всё таки он работал с net.inet.ip.dummynet.io_fast=0 ?
