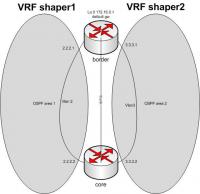
имеется тестовая схема
для объединения маршрутов 2-х таблиц, работает на core - bgp, он же и передает маршруты с core на border в случае падения одного из виланов
с хоста core (с обоих vrf) пингуется IP 172.16.0.1 бордера (default gw)
core#ping vr shaper1 172.16.0.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.0.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 20/57/100 ms
core#ping vr shaper2 172.16.0.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.0.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 48/74/156 ms
реально эти виланы (2, 3) будут идти по разным линкам между core и border
для резервирования добавляю на core статические маршруты с большей метрикой
ip route vrf shaper1 0.0.0.0 0.0.0.0 Vlan3 3.3.3.1 200
ip route vrf shaper2 0.0.0.0 0.0.0.0 Vlan2 2.2.2.1 200
пробую уложить один интерфейс vlan2 к примеру.
таблица маршрутизации vrf shaper1 до падения:
core#sh ip route vrf shaper1
Routing Table: shaper1
Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route
Gateway of last resort is 2.2.2.1 to network 0.0.0.0
2.0.0.0/24 is subnetted, 1 subnets
C 2.2.2.0 is directly connected, Vlan2
3.0.0.0/24 is subnetted, 1 subnets
B 3.3.3.0 is directly connected, 00:20:43, Vlan3
6.0.0.0/32 is subnetted, 1 subnets
C 6.1.1.1 is directly connected, Loopback6
O*E2 0.0.0.0/0 [110/1] via 2.2.2.1, 00:21:45, Vlan2
таблица маршрутизации vrf shaper1 после падения:
core#sh ip route vrf shaper1
Routing Table: shaper1
Codes: C - connected, S - static, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2
i - IS-IS, su - IS-IS summary, L1 - IS-IS level-1, L2 - IS-IS level-2
ia - IS-IS inter area, * - candidate default, U - per-user static route
o - ODR, P - periodic downloaded static route
Gateway of last resort is 3.3.3.1 to network 0.0.0.0
3.0.0.0/24 is subnetted, 1 subnets
B 3.3.3.0 is directly connected, 00:24:10, Vlan3
6.0.0.0/32 is subnetted, 1 subnets
C 6.1.1.1 is directly connected, Loopback6
S* 0.0.0.0/0 [200/0] via 3.3.3.1, Vlan3
пинг из vrf shaper1 до 172.16.0.1 пропадает, хотя маршрут по-умолчанию есть
vrf shaper2 продолжает работать нармально!
core#ping vr shaper1 172.16.0.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.0.1, timeout is 2 seconds:
.....
Success rate is 0 percent (0/5)
спустя несколько минут появляются сообщения о падении БГП пира:
*Mar 1 00:27:39.259: %BGP-5-ADJCHANGE: neighbor 2.2.2.1 vpn vrf shaper1 Down BGP Notification sent
*Mar 1 00:27:39.259: %BGP-3-NOTIFICATION: sent to neighbor 2.2.2.1 4/0 (hold time expired) 0 bytes
и пинг начинает проходить из vrf shaper1 до 172.16.0.1 по маршруту по-умолчанию
core#ping vr shaper1 172.16.0.1
Type escape sequence to abort.
Sending 5, 100-byte ICMP Echos to 172.16.0.1, timeout is 2 seconds:
!!!!!
Success rate is 100 percent (5/5), round-trip min/avg/max = 68/106/172 ms
как можно сократить время падения BGP соседа до нескольких секунд?
конфиг core:
hostname core
!
ip cef
!
ip vrf shaper1
rd 1:1
route-target export 1:1
route-target import 1:2
route-target import 1:1
!
ip vrf shaper2
rd 1:2
route-target export 1:2
route-target import 1:1
route-target import 1:2
!
interface Loopback0
ip address 5.1.1.2 255.255.255.255
!
interface Loopback6
ip vrf forwarding shaper1
ip address 6.1.1.1 255.255.255.255
!
interface FastEthernet1/0
switchport mode trunk
no ip address
duplex full
speed 100
!
interface Vlan1
no ip address
shutdown
!
interface Vlan2
ip vrf forwarding shaper1
ip address 2.2.2.2 255.255.255.0
shutdown
!
interface Vlan3
ip vrf forwarding shaper2
ip address 3.3.3.2 255.255.255.0
!
router ospf 1 vrf shaper1
log-adjacency-changes
network 2.2.2.0 0.0.0.255 area 1
network 10.0.0.0 0.255.255.255 area 1
!
router ospf 2 vrf shaper2
log-adjacency-changes
network 3.3.3.0 0.0.0.255 area 2
network 10.0.0.0 0.255.255.255 area 2
!
router bgp 1
no synchronization
bgp router-id 5.1.1.2
bgp log-neighbor-changes
no auto-summary
!
address-family ipv4 vrf shaper2
redistribute connected
redistribute ospf 2
neighbor 3.3.3.1 remote-as 1
neighbor 3.3.3.1 activate
no auto-summary
no synchronization
exit-address-family
!
address-family ipv4 vrf shaper1
redistribute connected
redistribute ospf 1
neighbor 2.2.2.1 remote-as 1
neighbor 2.2.2.1 activate
no auto-summary
no synchronization
exit-address-family
!
ip http server
ip classless
ip route 0.0.0.0 0.0.0.0 Vlan3 3.3.3.1 200
ip route vrf shaper1 0.0.0.0 0.0.0.0 Vlan3 3.3.3.1 200
ip route vrf shaper2 0.0.0.0 0.0.0.0 Vlan2 2.2.2.1 200
конфиг бордера:
hostname border
!
ip cef
!
interface Loopback0
ip address 172.16.0.1 255.255.255.255
!
interface Loopback1
ip address 172.16.1.1 255.255.255.0
!
interface FastEthernet1/0
switchport mode trunk
no ip address
duplex full
speed 100
!
interface Vlan1
no ip address
shutdown
!
interface Vlan2
ip address 2.2.2.1 255.255.255.0
!
interface Vlan3
ip address 3.3.3.1 255.255.255.0
!
router ospf 1
log-adjacency-changes
network 2.2.2.0 0.0.0.255 area 1
network 3.3.3.0 0.0.0.255 area 2
default-information originate
!
router bgp 1
no synchronization
bgp log-neighbor-changes
neighbor 2.2.2.2 remote-as 1
neighbor 3.3.3.2 remote-as 1
no auto-summary
!
ip http server
ip classless
ip route 0.0.0.0 0.0.0.0 Loopback0