Azamat
-
Публикации
316 -
Зарегистрирован
-
Посещение
Все публикации пользователя Azamat
-
Nexus 3064 - возник из ничего нереально большой трафик на SVI
тему ответил в Azamat пользователя Azamat в Активное оборудование Ethernet, IP, MPLS, SDN/NFV...
тв "сыплет" :( это из заметного. Через стандартный IP во влане управления недоступен. Медленно работает консоль, т.к. проц загружен вместо обычных 30-40 проц на 85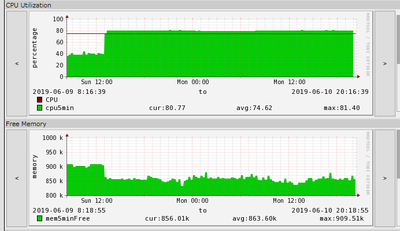
-
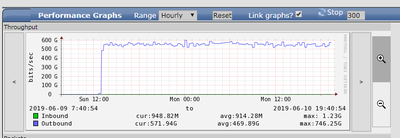
Доброго всем дня. Есть nexus 3064, на нем помимо всего прочего 4 svi интерфейса. Вчера в одно и тоже время на всех svi возник из ничего нереально большой исходящий трафик - например, обычный трафик на 2 svi - порядка 1,2 гиг на каждом. Сейчас исходящий судя по графику - 560Гиг на каждом. На 3-м svi обычный трафик 100Кбит/с - влан управления - сейчас на нем исходящий 300Гиг. Доступ только через mgmt порт, через IP адрес на svi управления - скидывается. Реально, нет событий, к которым можно было бы привязать взрыв трафика. Пытались зеркалировать - ничего не видать, вроде т.к. в зеркало на source vlan идет только rx, а взрывной трафик по tx. А сделать source int vlanXXX не дает. Версия 6.ХХХ Из странного еще хороший прирост процесса bcm_usd. На физических интерфейсах - ничего примечательного, все как до взрыва трафика. Пытались делать shutdown на int влана управления - мин 10 держали, потом подняли - ничего не изменилось. В общем может кто подскажет, как можно хоть что-то отдебажить до перезагрузки, которую запланировали на 6 утра ? Может есть возможность убить процесс с HUP ? Сам не нашел, как именно - ибо ремесленники мы. Добавил график.