nshut
-
Публикации
60 -
Зарегистрирован
-
Посещение
О nshut
-
Звание
Абитуриент
")
-
Linux NAT
тему ответил в junjunk2 пользователя nshut в Программное обеспечение, биллинг и *unix системы
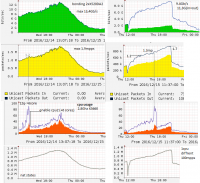
В общем поигрался я и с очередями через исходники, и с разными ядрами и еще много чем. Разница в использовании на одном процессоре бондинга и без него составила 100mpps, что примерно 8% от общей производительности, т.е. не загрузка процессора, а именно производительность железа и текущей конфигурации. Тест проводится с идентичными настройками, бондинг был разобран без перезагрузки. Двух процессорный результат получить не удалось, т.к. уперся в полку сетевой. Для себя сделал вывод, 100мппс погоды не играют, т.к. на графиках видно, что сервер когда достигает критического момента производительности, следующие 50-100мппс уложат его в полку, а работа на пределе, это любой флуд сделает ваш сервер трупом. Возможно мои показатели и настройки ужасные, я продолжаю экспереминтировать пока. Тесты проводились на X5660 @ 2.80GHz, память 3CH 1333, сетевая X520da2, сервисы 25правил iptables (есть ipset и xmark), ipt_netflow, весь трафик NATится в 3 подсети. Ядро линукса: до этого было 3.10.104, последние тесты на ядре 3.18.45, интересный момент, последнее показывает загрузку на 10-15% меньше в общем, но полка наступает одновременно, т.е. ложит сервер мппс и никаких улучшений в эту сторону не сделано. Когда наступает полка: игры с usec_rx и другими умными параметрами сильно результата не дают, т.е. тупо нехватает Mpps vs (частота*ядра). Один проц производительнее двух, вымывание кэша в разы меньше, но частота дополнительных ядер отодвигает полку. Отсюда вывод: один проц с кучей ядер и максимальной частотой, точно лучше двух в сумме частота*ядра.