mirk
-
Публикации
41 -
Зарегистрирован
-
Посещение
-
Linux softrouter
тему ответил в Dark_Angel пользователя mirk в Программное обеспечение, биллинг и *unix системы
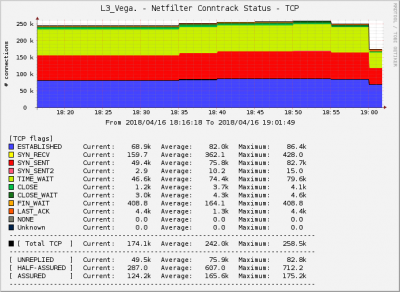
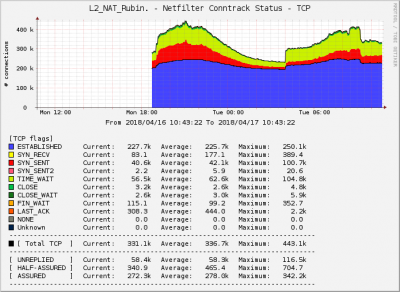
Нет обе карты на слотах CPU1 в материнке. Сегодня попробую убрать бондинг. Реально трафика больше 10G и он каждый месяц растёт. Просто в тестах не стали давать больше когда столкнулись с проблемой. У нас есть решение из 2х машин одна шейпит вторая натит. Хотели сделать всё на одной более мощной. Гипертрейдинг отключен. Как писал выше у нас есть решение из 2х машин одна шейпит вторая натит. Такая связка без особых проблем переваривает 10G. Но 2 машины занимают в 2 раза больше места и в 2 раза менее надёжны. С ростом трафика нам понадобились ещё мощности вот и решили попробовать все на одной собрать. Сегодня попробую убрать одну карт и посмотреть что будет. Ещё интересный момент. Настроил сбор данных по conntrack и графики меня смущают. На новом сервере соотношение Estableshed, time_wait и syn_sent совсем не такое как на старых серверах. Новый Старый